k-En Yakın Komşu Algoritması (k-Nearest Neighbor Algorithm) uzaklık hesaplamasına dayalı geliştirilen bir sınıflandırma yöntemidir, benzerliğe dayalı bir algoritmadır. Sınıfı bilinmeyen verinin diğer verilere olan uzaklıklarının hesaplanarak, en yakın sınıfa dahil edilmesi mantığına dayanır. O yüzden öncelikle veriler arasındaki uzaklıkların hesaplanmasında kullanılan yaygın yöntemler üzerinde durulmalıdır.
Hangi uzaklık ölçüsünü kullanacağınızı bilmenizde fayda var: Öklid Mesafesi, Minkowski uzaklık, Manhattan uzaklık, Jaccard katsayısı
The 'metric' parameter of KNeighborsClassifier must be a str among {'l2', 'sokalmichener', 'p', 'infinity', 'matching', 'chebyshev', 'l1', 'euclidean', 'canberra', 'mahalanobis', 'nan_euclidean', 'minkowski', 'rogerstanimoto', 'precomputed', 'hamming', 'jaccard', 'yule', 'dice', 'wminkowski', 'cityblock', 'kulsinski', 'sqeuclidean', 'correlation', 'pyfunc', 'russellrao', 'sokalsneath', 'cosine', 'manhattan', 'haversine', 'seuclidean', 'braycurtis'}
Python İle KNN Sınıflandırma
#1. kutuphaneler
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
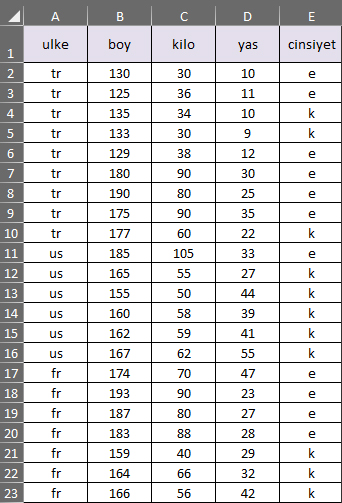
veriler=pd.read_csv("veriler.csv")
#ulke,boy,kilo,yas,cinsiyet
x=veriler.iloc[:,1:4].values
y=veriler.iloc[:,4:].values
#Şimdi Train ve Test olarak ayırma işlemi yapalım
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.33,random_state=0)
#STANDARTLAŞTIRMA
from sklearn.preprocessing import StandardScaler
sc=StandardScaler()
X_train=sc.fit_transform(x_train)#fit_transform
X_test=sc.transform(x_test)#transform
#KNN
from sklearn.neighbors import KNeighborsClassifier
knn_r=KNeighborsClassifier(n_neighbors=1,metric='minkowski')
knn_r.fit(X_train,y_train)#X den Y öğren
#şimdi öğrendiğin bilgi ile predict-tahmin yap
y_pred=knn_r.predict(X_test)
print(y_pred)
print(y_test)
#CONFUSION MATRİX-HATA MATRİSİ
from sklearn.metrics import confusion_matrix
cm=confusion_matrix(y_test,y_pred)
print(cm)
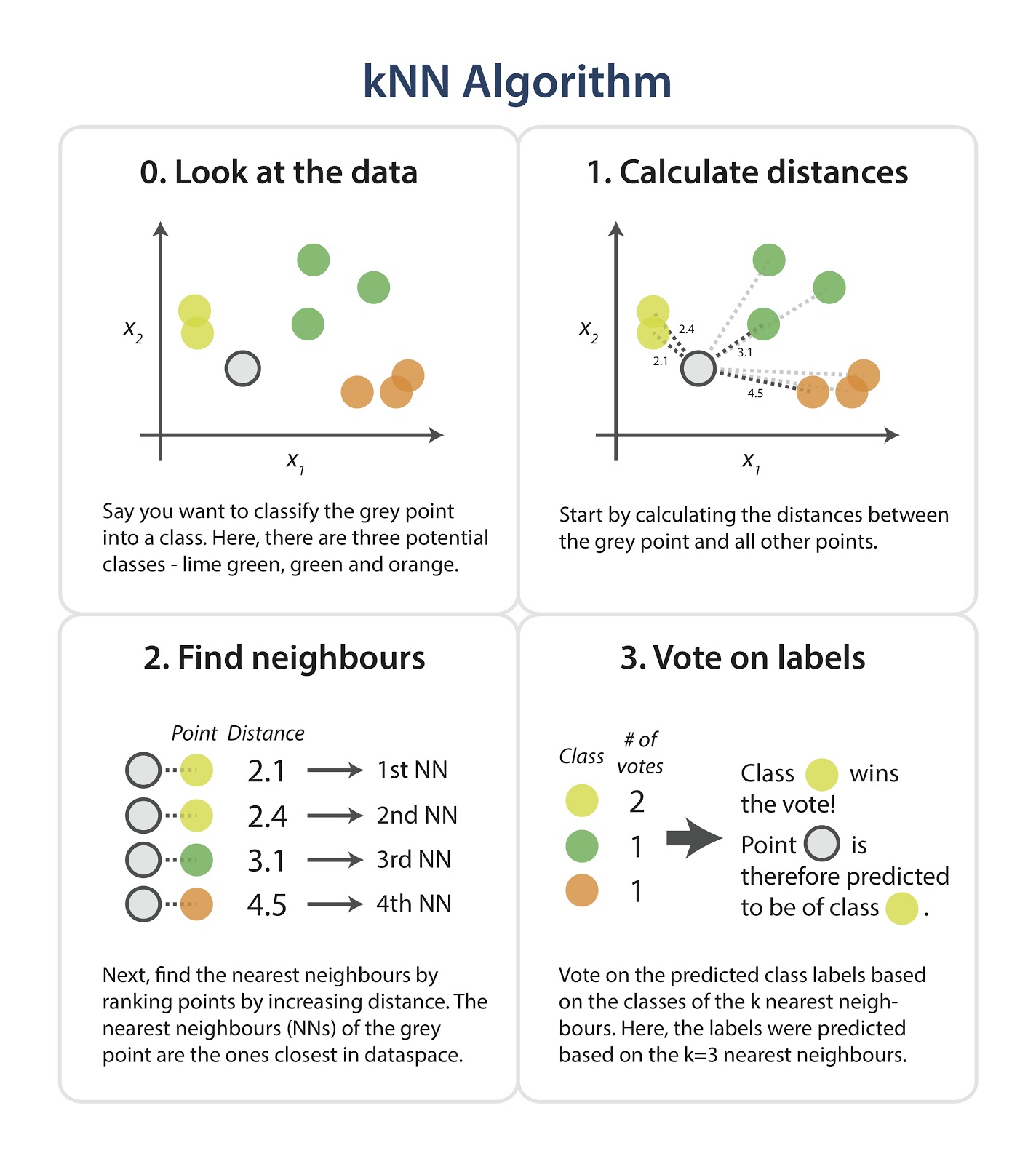
K-En Yakın Komşu (KNN), benzerlik ilkesine dayanan basit ve sezgisel bir denetimli makine öğrenmesi algoritmasıdır. Hem sınıflandırma hem de regresyon problemlerinde kullanılabilir.
Hayal edin ki elinizde kırmızı ve mavi noktaların bulunduğu bir dağılım grafiği var. Bu noktalar, kırmızı olanlar bir sınıfı, mavi olanlar ise başka bir sınıfı temsil ediyor. Şimdi elinize daha önce hiç görmediğiniz yeni bir nokta geçti ve bu noktanın hangi sınıfa ait olduğunu tahmin etmek istiyorsunuz.
İşte KNN bu noktada devreye giriyor: Bu yeni veriye en yakın olan “K” adet komşu noktayı buluyor (K, sizin belirlediğiniz bir hiperparametredir). Diyelim ki K = 3 ve bu yeni noktaya en yakın 3 noktadan 2’si kırmızı, 1’i mavi.
Bu durumda KNN, yeni noktayı çoğunluk olan sınıfa (kırmızıya) atar. Yani kısaca: “En yakın komşuların kimse, sen de onlardansın” mantığıyla çalışır.
K-En Yakın Komşu (K-NN) Algoritması ile Satın Alma Tahmini
1. Giriş
Bu döküman, Social_Network_Ads.csv veri kümesindeki yaş ve maaş bilgilerine göre satın alma tahminini yapmak amacıyla bir K-En Yakın Komşu (K-NN) sınıflandırıcısının uygulanmasını açıklamaktadır. İş akışı veri ön işleme, model eğitimi, değerlendirme ve analiz adımlarını içerir.
2. Kütüphanelerin Yüklenmesi
Aşağıdaki Python kütüphaneleri kullanılmaktadır:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
3. Veri Kümesinin Yüklenmesi
Veri kümesi yüklenir ve ilk 5 satır görüntülenir:
import kagglehub
# Download latest version
path = kagglehub.dataset_download("akram24/social-network-ads")
print("Path to dataset files:", path)
df = pd.read_csv("/kaggle/input/social-network-ads/Social_Network_Ads.csv")
df.head()
Çıktı (ilk 5 satır):
User ID Gender Age EstimatedSalary Purchased 0 15624510 Male 19 19000 0 1 15810944 Male 35 20000 0 2 15668575 Female 26 43000 0 3 15603246 Female 27 57000 0 4 15804002 Male 19 76000 0
USER ID kullanılmayacağı için çıkarılmalı:
#Kullanılmayacak User ID sütununu çıkar
df = df.drop("User ID", axis=1)
Gender sütunu one-hot encoding yapılmalı
df = pd.get_dummies(df, columns=['Gender'], drop_first=True)
Öznitelikler X (Age, EstimatedSalary, Gender_Male) ve hedef Y(Purchased) değişkenleri ayrılır:
# X: Purchased hariç tüm sütunlar
X = df.drop("Purchased", axis=1).values
# Y: Doğrudan sütun adıyla al
Y = df["Purchased"].values
4. Veri Kümesinin Bölünmesi
Veri kümesi %80 eğitim ve %20 test olarak bölünür:
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.2, random_state=45)
5. Özellik Ölçekleme
Özellikler, K-NN’in mesafe metriğinin ölçekten etkilenmemesi için standartlaştırılır:
Sc = StandardScaler()
X_train = Sc.fit_transform(X_train)
X_test = Sc.transform(X_test)
6. K-NN Modelinin Eğitilmesi
K-NN sınıflandırıcısı, 5 komşu ile ve Öklid uzaklığı metriği kullanılarak eğitilir:
classifier = KNeighborsClassifier(n_neighbors=5, metric="minkowski", p=2)
classifier.fit(X_train, Y_train)
7. Yeni Bir Sonucun Tahmini
Yeni bir veri (Age=30, EstimatedSalary=87000, Gender_Male=True) için modelin tahmini:
print(classifier.predict(Sc.transform([[30, 87000,True]])))
Çıktı: [0]
8. Test Sonuçlarının Tahmini
Modelin test verisi üzerindeki tahminleri ve gerçek değerler karşılaştırılır:
y_pred = classifier.predict(X_test)
print(np.concatenate((y_pred.reshape(len(y_pred), 1), Y_test.reshape(len(Y_test), 1)), 1))
Çıktı (ilk 5 satır):
[[1 1] [1 1] [0 0] [1 1] [0 0]]
9. Karışıklık Matrisi Oluşturulması
Modelin başarımı karışıklık matrisi ve doğruluk skoru ile değerlendirilir:
from sklearn.metrics import confusion_matrix, accuracy_score
cm = confusion_matrix(Y_test, y_pred)
print(cm)
accuracy_score(Y_test, y_pred)
Çıktı:
[[45 3] [ 3 29]]
Doğruluk: 0.925 (92.5%)
10. Analiz
K-NN sınıflandırıcısı test kümesinde %92.5 doğruluk elde eder. 45 doğru negatif, 29 doğru pozitif, 3 yanlış pozitif ve 3 yanlış negatif gözlemlenmiştir. Bu yüksek doğruluk, yaş ve maaş gibi sayısal özniteliklerin sınıfları etkili bir şekilde ayırdığını gösterir. Ancak, 6 yanlış sınıflandırma modeli iyileştirme fırsatlarına (komşu sayısının ayarlanması, özellik etkileşimlerinin analiz edilmesi gibi) işaret eder.
Kaynaklar
- https://www.youtube.com/watch?v=NEAxrOP_OT0
- https://ichi.pro/tr/k-en-yakin-komsular-ile-k-ortalama-kumeleme-arasindaki-fark-nedir-36508279026525
- https://twitter.com/levikul09/status/1672896169763303424
- https://machinelearningmastery.com/types-of-classification-in-machine-learning/
- https://www.digitalocean.com/community/tutorials/k-nearest-neighbors-knn-in-python
- https://www.instagram.com/reels/DVai_Atkjf3/